文 | 字母榜
确切吵杂的一周。
周一,Kimi刚发完Kimi K2.6;周五,万众注目的DeepSeek V4就来了。
这种嗅觉很熟习。
往常一年,这两家公司不是前后脚发模子,等于前后脚发时间论文,不是你把阛阓热度点着了,等于我把时间计议接往常了。
更早之前,提及中国开源模子,险些条款反射地思到DeepSeek。
尤其是DeepSeek发布R1之后,这家公司不仅凭一己之力改写了人人阛阓对中国AI的印象,况兼叫醒了其他中国的AI创业团队的“信心”。
于是,咱们看到,更多的中国AI创业团队运转作念出颠倒竞争力的模子,带来颠倒有影响力的时间相干收尾。
2025年7月,被《当然》杂志称为“又一个DeepSeek时刻”的Kimi K2模子,在底层架构上初度大鸿沟考据了二阶优化器 Muon,同期给与了 DeepSeek考据过的 MLA留心力机制。
到了2026年4月,DeepSeek V4在架构上也跟进 Kimi K2给与 Muon优化器,取代往常一经使用了10年的Adam优化器。
这可能是开源最大的价值:让中国公司分享时间,加快追逐好意思国的闭源巨头。
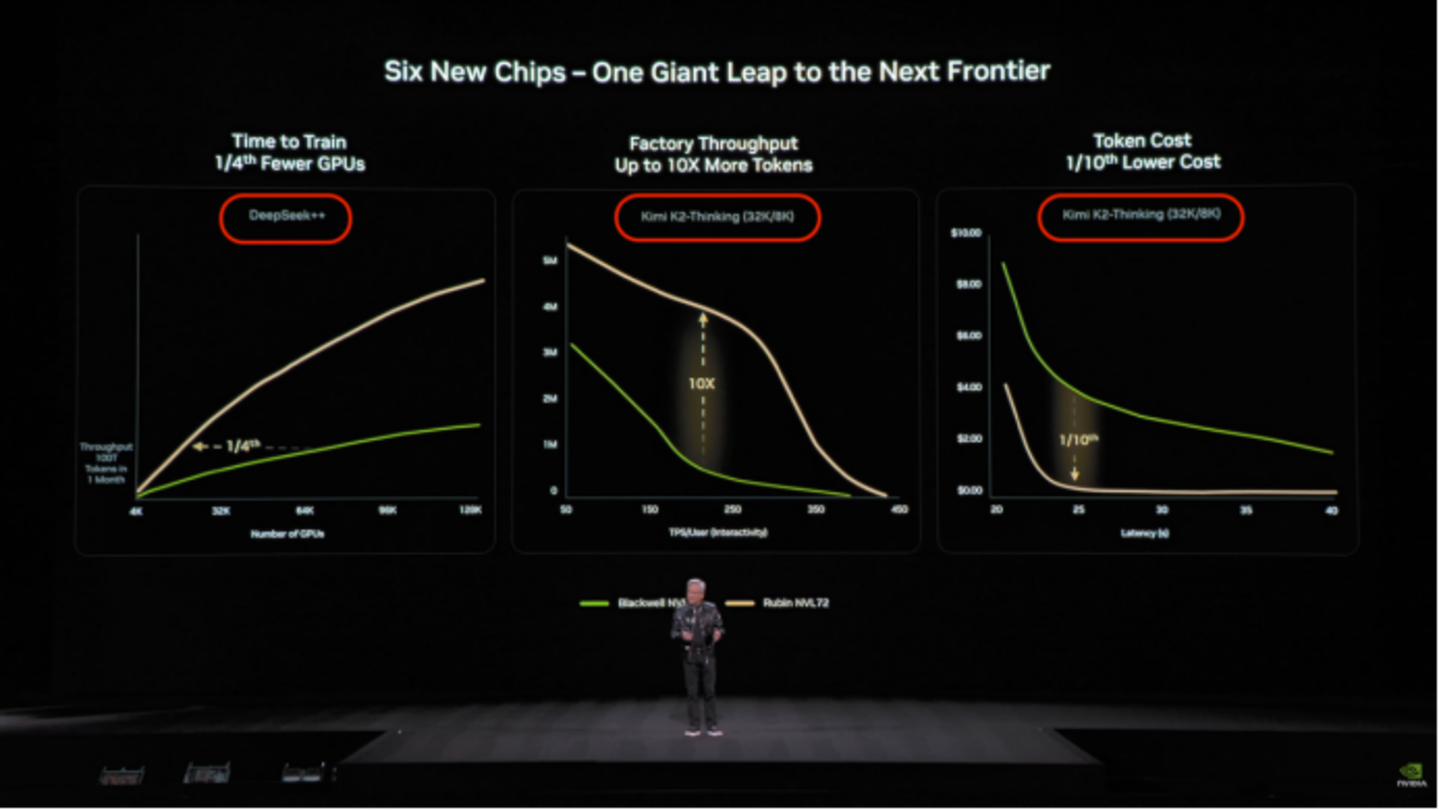
它们是中国面前唯二,总参数卓越万亿、已权重公开的中国模子。亦然最有海外影响力的中国AI模子代表。人人市值最高的英伟达公司在展示下一代芯片性能时,用的模子恰是来自 DeepSeek 和Kimi。
不仅如斯,他们也齐在挑战深度学习蚁集的底层架构,DeepSeek有mHC残差贯串,Kimi有激发硅谷中枢时间圈计议的“留心力残差”。
01
诚然说DeepSeek V4和Kimi K2.6在吞并周发布,但其实两个模子各恐怕间侧重心。
V4的中枢突破在于百万陡立文的本钱重构,它通过全新的搀和留心力机制,将单token推理的计较量压缩到V3.2的27%,KV Cache降至10%。
这套决策纠合了压缩稀薄留心力和重度压缩留心力,让百万级陡立文从时间演示变成了不错普及的基础设施。
V4同期针对agent场景作念了专项优化,后覆按阶段把agent动作孤苦标的单独覆按,器用调用体式从JSON换成带额外token的XML结构,跨轮次推理陈迹在器用调用场景下齐全保留。
DeepSeek还自建了名为DSec的沙箱平台,单集群可并发料理数十万个沙箱实例,用来撑持agent强化学习覆按和评测。
K2.6的标的则更偏向长程编码和agent集群。它在Kimi Code Bench里面评测中得分68.2,比K2.5的57.4升迁约20%。
最高可援助300个子agent并行完成4000个勾搭门径。
02
2025年2月,Kimi 发布 Moonlight系列模子,初度将二阶优化器Muon诓骗于480亿参数的大模子,考据了新一代优化器的效果。
2025年4月,Kimi-VL模子发布,在Moonlight模子的时间上,引入MoonViT视觉编码器,为之后的多模态意会模子打下基础。
2025年7月,Kimi初度将Muon优化器推广到万亿参数的鸿沟,推出 K2 开源模子。
2025年10月,Kimi发布Kimi Linear,这是Kimi提议的一种线性留心力架构,中枢盘算是在保住长陡立文智商的同期,把大模子处理超长文本的计较和显存本钱降下来。
这施展杨植麟一经不得志于只作念模子了,他思对模子的底层架构最先。
随后,Kimi发布并开源援助图片和视频意会的万亿参数模子Kimi K2.5。
2026年3月,Kimi发布留心力残差的论文,不绝对Transformer的底层结构下手。
这篇论文在X上收成了马斯克本东说念主的赞叹。
在然后就到了前几天的K2.6,这是一个围绕长周期编码、agent现实、工程任务智商的模子。
从居品定位的演变不错看出,Kimi正在从破钞级对话居品往分娩力器用转型。
2026年3月,杨植麟在英伟达GTC大会上发扮演讲,系统先容Kimi时间阶梯,他用三个重要词玄虚Kimi的Scaling计谋:Token效劳、长陡立文、agent集群。
他暗示,要鼓动大模子智能上限的陆续突破,必须对优化器、留心力机制及残差贯串等底层基石进行重构。
面前的Scaling一经不再是单纯的资源堆砌,而是要在计较效劳、长程讲究和自动化勾搭上同期寻找鸿沟效应。
一家公司最怕的是,唯独媒体在计议你,开导者却不必你。
但Kimi不相同,岂论是在OpenRouter上如故绝大多半agent器用的默许接口里, K2.5和K2.6齐是主流选项。
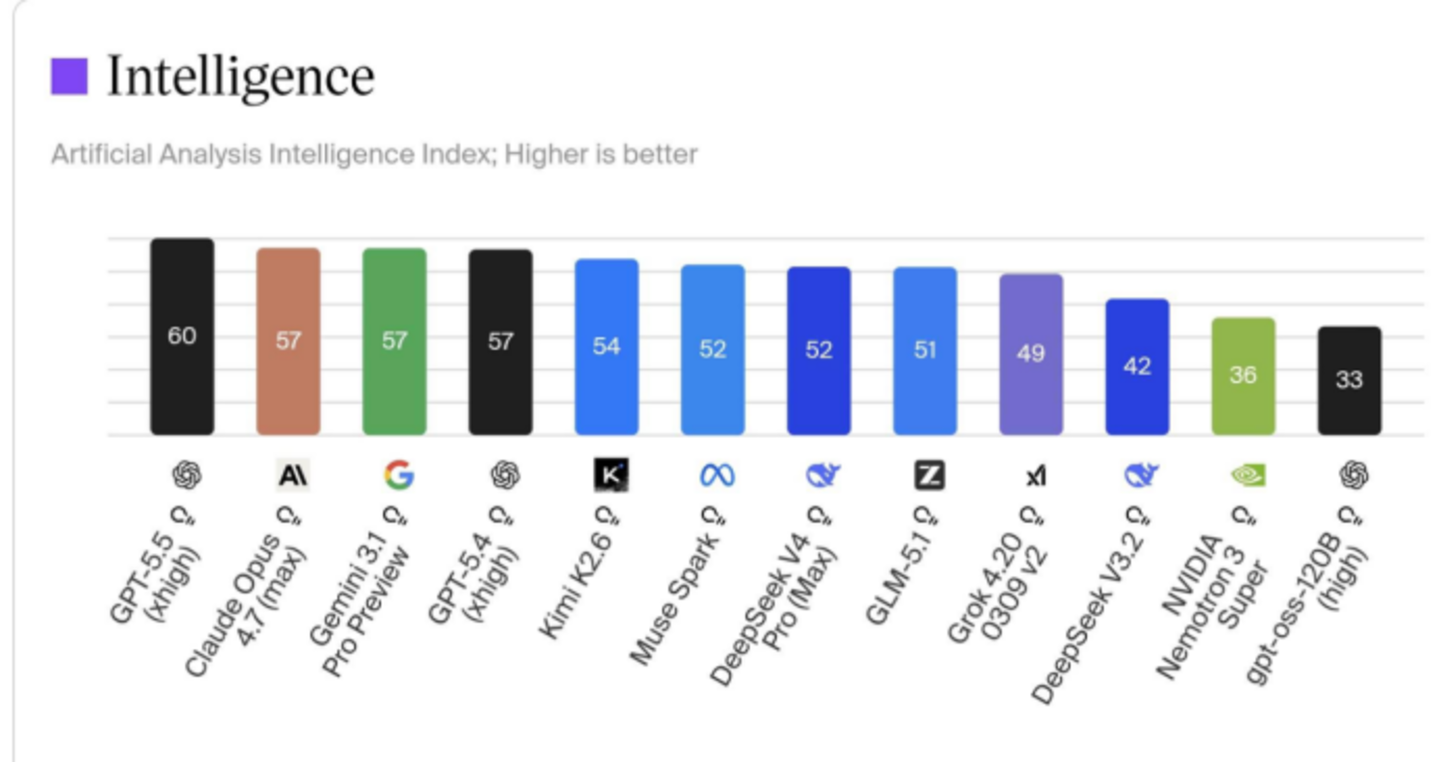
死一火发稿,Kimi和DeepSeek齐出面前OpenRouter的TOP3模子里,在AA的榜单上,K2.6致使暂时占得先机。
而在K2.6这里,模子不绝强化agent、长任务、编码智商,亦然吞并个信号。杨植麟真实押注的,等于分娩力场景。
这亦然Kimi这一年最重要的变化。
它不再仅仅告诉用户“我能帮你读更长的文献”,而是在陈述更底层的问题,模子若何武艺在更万古辰、更复杂任务、更高器用调用密度下保持踏实?
长陡立文科罚的是讲究和信息承载;线性留心力科罚的是本钱和推广性;agent集群科罚的是复杂任务拆解;编程智商科罚的是模子的意会和现实。
它们看起来是几条不同居品线,其实背后指向吞并个标的,Kimi思把Kimi从一个好用的聊天窗口,变成不错连续真实职责的基础模子。
4月,杨植麟受邀参加总理主理的经济形状大师和企业家茶话会,动作独一的大模子创业者代表发言。这个1993年降生的年青东说念主,成为茶话会上最年青的参会者。
一个月前,他刚在2026中关村论坛年会整体会议上发扮演讲,系统进展了中国AI团队若何通过底层架构的“推倒重建”,冲破沿用十年的行业时间措施。
显然,Kimi一经从一家创业公司,变成了代表中国AI时间阶梯的记号之一。
Kimi这一年的成长旅途,和DeepSeek的旅途有显然各别。两家公司的时间选拔不同,但也正因如斯,才让中国开源模子有了更多可能性。
03
往常咱们写这两家公司,容易写成“谁的模子好”、“谁才是下一个OpenAI”。
但这其实是个误区。
DeepSeek和Kimi,不该被浅薄意会成“谁赢谁输”。它们更像中国开源模子对外竞争的两条腿。不存在谁取代谁,而是应该相互刺激相互促进。
DeepSeek和Kimi接踵讲解了一件事,作念前沿模子不一定需要无穷的资源,重要在于算法编削和工程优化。它们在模子算法、工程效劳、开源阶梯和裁减推理本钱上的孝敬,仍然是中国AI往常一年最迫切的时间事件之一。
它们相互竞争,但也相互举高了中国开源模子的上限。
真实迫切的不是它们谁先到极端,而是它们把中国模子的竞争维度赶走了。
往常咱们评价一家模子公司,很容易只看榜单、参数、价钱、发布会声量。
但模子公司真实的护城河,一经不再是“模子聪不机灵”、“模子性能若何”这些事了。面前围绕模子的叙事,是它能不可变成一整套时间阶梯。
DeepSeek把第一件事作念得很透顶。它让外界看到,中国公司不错用更高的工程效劳,把模子覆按和推理本钱打下来,不错把时间讲述写到迷漫透明,不错把权重绽开到迷漫激进。
它建造的是一种开源信任。开导者愉快相干它、复现它、部署它,是因为它不仅仅给了一个API,而是把模子背后的方法论也拿了出来。
Kimi补上的是另一块。
Kimi最早被用户记着,是因为长文本和聊天居品,但K2.6之后,它讲的一经不是一个更会聊天的助手,而是模子若何插足真实职责流。
长程编码、Agent集群、器用调用、长周期任务,这些智商莫得“霸榜”那么直不雅,但它们决定模子能不可从“被试用”走向“被依赖”。
淌若说DeepSeek科罚的是模子够不够强、够不够低廉、够不够绽开的问题,Kimi更眷注的是模子能不可真的替东说念主完成复杂任务。
是以这两家公司放在一齐看,真理反而更大。
动作不雅察者和用户,咱们笃定但愿齐存在,这么产业武艺发展。
中国AI真适值得慷慨的,不是终于出了一个DeepSeek。
而是在DeepSeek的带动下,Kimi们依然能靠我方成长为一座座大山。
这施展中国AI公司一经运转在不同维度上找到我方的位置,不再是浅薄师法,是真实的在探索我方特有的那条时间阶梯。
DeepSeek和Kimi的时间相互赋能,也施展了一件事,开源生态的价值在于勾搭。
面前的问题不是DeepSeek和Kimi谁更强,而是它们能不可不绝保持这种竞争关连,不绝在时间上相互刺激。
中国开源模子要真确凿人人站稳脚跟,需要的不是一家独大现金巴黎人娱乐城app平台,而是多家公司在不同方朝上齐作念到宇宙级水平。DeepSeek和Kimi的存在,让这个可能性变得更大。